1. Kafka Topic
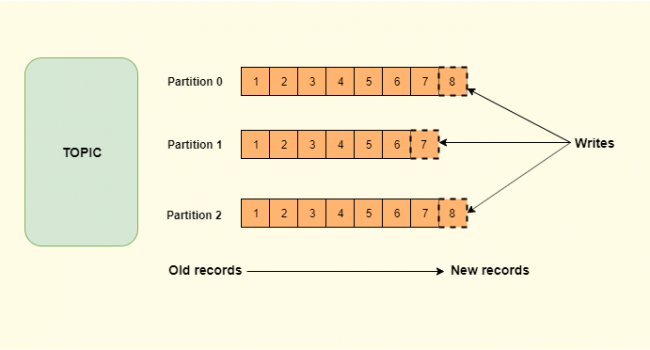
Topic is a stream of messages belonging to a particular category, data is stored in topics. Topics are divided into partitions. For each topic, Kafka maintains atleast one partition. The order of each record/message in a partition is immutable. The topics by default is multi-subscriber, a topic can have zero or many consumers subscribed and waiting for the data to be written to it.
2. Partition
Partition is an ordered sequence of records, the order is immutable and data gets appended to the partition in the order as they are written. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
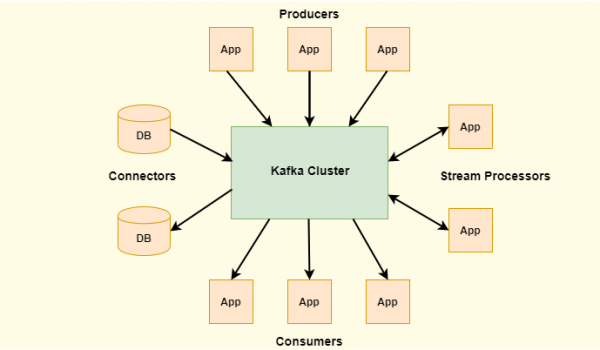
3. Producers
Kafka producers are the message originator, producers can write messages to one or more Kafka topics. Producers send the message brokers, upon receiving the message broker simply appends the message to one of the partitions in the topic. Producers can also send messages to a particular partition of a topic.
4. Consumers
Kafka consumers has to subscribe to one or more topics in order to consume/read the message from the topics. Kafka consumer read data from brokers for a particular topic to which it has subscribed.
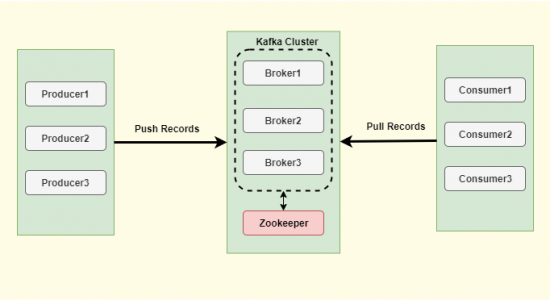
5. Brokers
Brokers are a group of systems which are responsible for maintaining the published data. The producers and consumers always gets connected to a list of brokers, where the data can be published/consumed. Each broker may have one or more partitions per topic. For example if there are X partitions in a topic and X number of brokers, each broker will have one partition as master and other partition as follower and these partition will be replicated across brokers.
6. Zookeeper
Kafka uses ZooKeeper for managing and coordinating group of Kafka broker. ZooKeeper service is mainly used to form and maintain the kafka cluster. Zookeeper is mandatory for kafka to function, as it is used for cluster management of kafka broker, replication of the data across brokers, storing of consumer last read/processed partition index so that the consumer can resume from where it was last left. Each topic might have one or more partition, Zookeeper decides which partition will be a master in which broker(other brokers will have a replica of the same partition but acting as a follower).
7. Leader
Leader is a node(one of the brokers) within the kafka cluster, which is responsible for all reads and writes to a particular partition of a topic. Brokers node can be a leader or follower for a particular partition of a topic. Every partition has one broker acting as a leader and other brokers as followers.
8. Follower
Follower is a node within the kafka cluster, which follows leader instruction for a given partition of topic. Follower are means to keep the data replicated, If the current leader fails, one of the followers will automatically become the new leader. A follower always pulls messages and updates its own data store.
9. Consumer Group
Each consumer will have a unique Id knowns as groupID. Consumer Group is a set of consumers with same consumer group ID. One consumer instance reads the data from one partition in one consumer group, at the time of reading. Since, there is more than one consumer group, in that case, one instance from each of these groups can read from one single partition, there will be some inactive consumers, if the number of consumers exceeds the number of partitions.